
Image Caption Generator using CNN and LSTM
Technologies Used
- Pytorch
- Python
- Spacy
Design
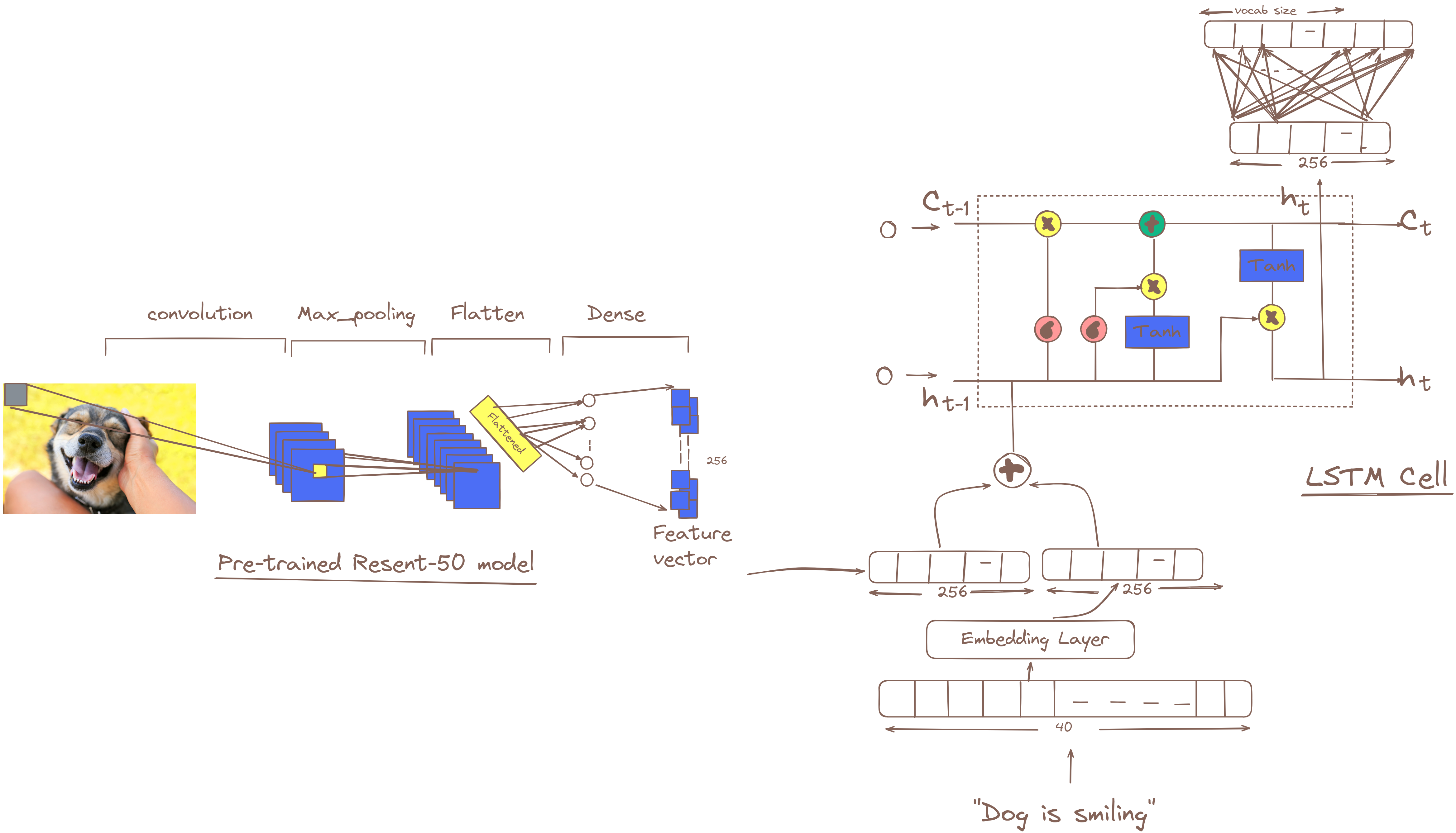
Training:
- Last layer of CNN module is removed, and fully connected layer is added that results in the feature vector of size (eg., 256). If batch_size=8, the ouput from cnn module will be of shape (8, 256)
- For each target word it produces 256 length of embedding by passing through the embedding layer. Here the sentence of max_length=40 is used. so the output of embedding layer will be (8, 40, 256), considering batch_size=8.
- The feature_vector from cnn_module and output of embedding_layer is concatenated to result in (8, 41, 256). This input shape is passed to the LSTM cell, which produces the 256 length of hidden_state and cell_state. After the, fc-layer is used to map the 256 length of feature vector to vocab_size=7500+(around). The ouput shape should be (8, 40, 7500+). considering, vocab_size = 7500+
- This above process occurs for the 40th time step, cause lstm process the sequence word by word. The training happens end-to-end.
Inference:
-
The Image passes through CNN module to generate feature vector of size 256.
-
This feature vector passes to lstm cell.
-
The lstm results on the probability distribution of words in vocab_size.
-
Loops for 40(max_length), until token is found. – The embedding of ouput word is then passed as input to lstm cell.
Examples
