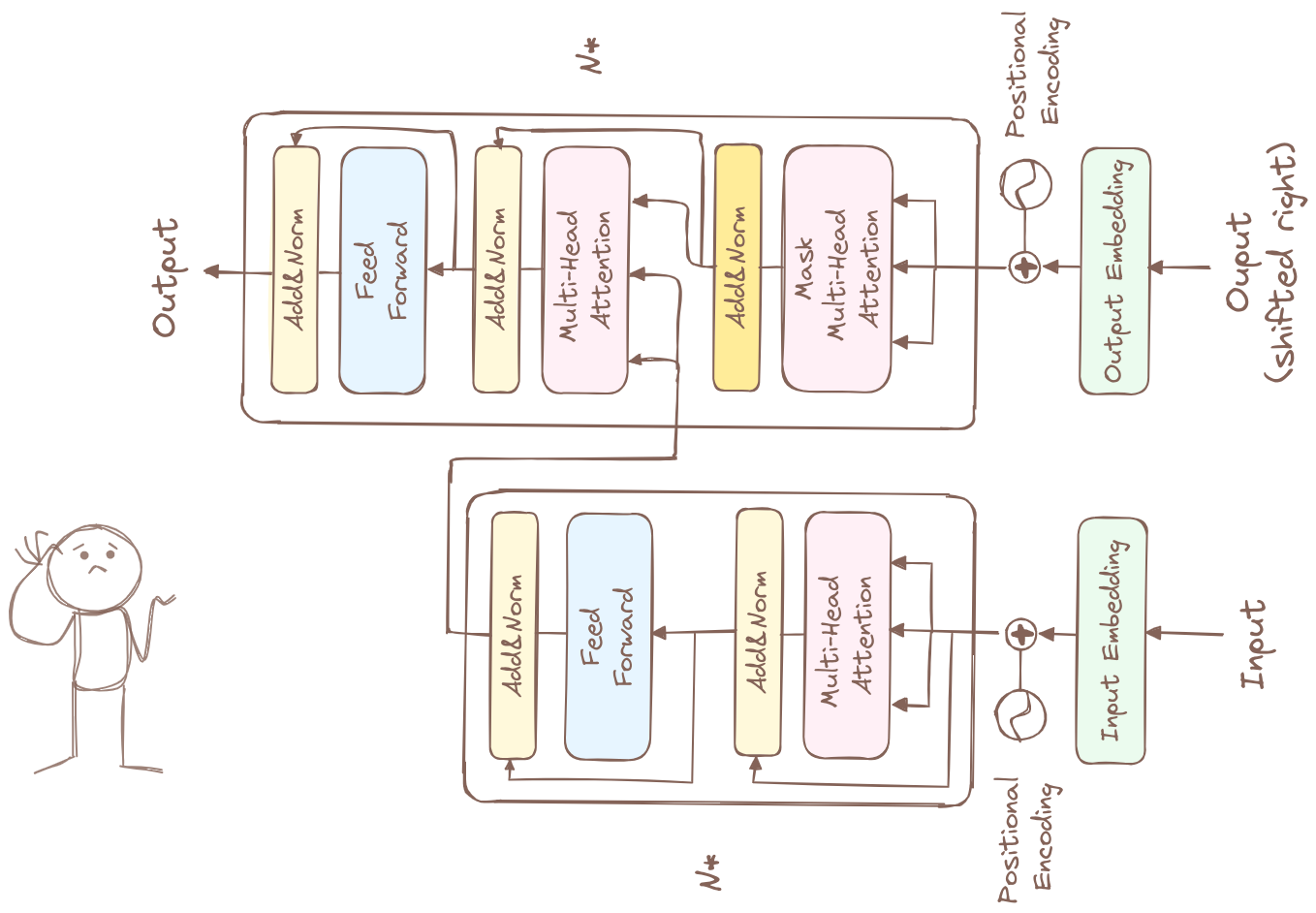
Transformer is a seq2seq model proposed by 8 Google employees in 2017 and initially applied to neural machine translation. But before transformer, let’s discuss what were used for the seq2seq task and their cons.
Recurrent Neural Network(RNN)
Given a sequences X_n it produces sequence of Y_n.
In t time step, it takes the given input and previous hidden state as input to produce ouput and hidden state which act as input for t+1. So, if n token were used to map it would take n time steps to generate n output sequence.
Problems with RNN
- Slow for longer sequences
It cannot process elements of a sequence in parallel because each step depends on the previous hidden state. - Slow Training
Back Propagation throguh time has to unfold network for each time step. - Exploding/Vanishing Gradients
- Limited Long term dependency
Difficulty maintaining and utilizing context from earlier in the sequence when making predictions about later parts of the sequence.
Transformer solves all these problems. Let’s break down transformer parts by parts.